
|
 27-11-2013, 17:36
27-11-2013, 17:36
|
#1 |
 |
Robot.TXT Kullanımı
robots.txt dosyası web’i tarayan arama motoru robotlarının sitenize erişimini kısıtlar. Bu botlar otomatiktir ve bir sitenin sayfalarına erişmeden önce, belirli sayfalara erişmelerini önleyen bir robots.txt dosyası olup olmadığını kontrol ederler.
Sitenizde arama motorlarının dizine eklemesini istemediğiniz içerikler varsa, robots.txt dosyası kullanılmalıdır. Arama motorlarının sitenizdeki her şeyi dizine eklemesini istiyorsanız, robots.txt dosyasına ihtiyacınız yoktur. Özetle; sayfanızın googlebot tarafından taranmasını robots.txt dosyası yardımıyla sınırlandırabilirsiniz. “robots.txt” olarak adlandırılması gereken bu dosya sitenizin kök dizininde olmalıdır. 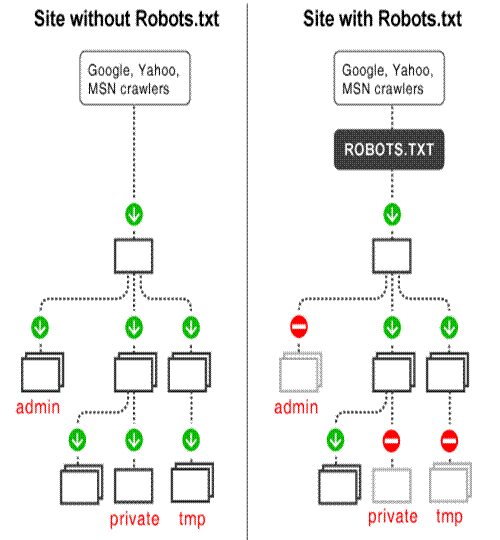 ROBOT.TXT DOSYASI OLUŞTURMA En basit robots.txt dosyası iki kural kullanır: User-agent: Aşağıdaki kuralın geçerli olduğu robot Disallow: Engellemek istediğiniz URL Bu iki satır, dosyada tek bir giriş sayılır. İstediğiniz kadar giriş ekleyebilirsiniz. robots.txt dosyasındaki her bölüm ayrıdır. Tek girişe birden çok Disallow satırı ve birden çok user-agent ekleyebilirsiniz. Örnek: HTML-Kodu:
User-agent: * Disallow: /klasor1/ User-Agent: googlebot Disallow: /klasor2/ HTML-Kodu:
<meta name="robots" content="noindex" />
“robots” direktifi tüm tarayıcılar için geçerli olduğunu belirtir. Sayfa taramasını sadece googlebot için, önleyecekseniz aşağıdaki etiketi kullanın: HTML-Kodu:
<meta name="googlebot" content="noindex" />
Ayrıca hassas veya gizli bilginin robots.txt ile bloke edilmesi sizi tamamen rahatlatmasın. Eğer bu bağlantılar internette başka bir yerde referans olarak verilmişse (örneğin referans veren bloglarda), bloke ettiğiniz URL’ler arama sonuçlarında referans olarak görüntülenebilir. |

|
Alıntı |
| Konuyu Toplam 1 Üye okuyor. (0 Kayıtlı üye ve 1 Misafir) | |
|
|
 Normal
Normal
